



 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
将12位的数据序列用(24,12)线性分组码编码,假定该码能纠正所有1位和2位的错误,但不能纠正多于2位的错误,求当信道错误率为10-3时接收消息译码错误率。
将12位的数据序列用(24,12)线性分组码编码,假定该码能纠正所有1位和2位的错误,但不能纠正多于2位的错误,求当信道错误率为10-3时接收消息译码错误率。
 答案
答案
查看答案

 用2路合并算法将这k个序列合并成一个序列.假设采用的2路合并算法合并2个长度分别为m和n的序列需要m+n-1次比较.
用2路合并算法将这k个序列合并成一个序列.假设采用的2路合并算法合并2个长度分别为m和n的序列需要m+n-1次比较.
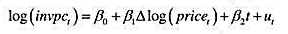
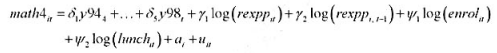
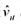 。
。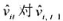 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。

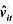 。
。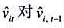 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。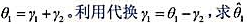 的标准误。
的标准误。


















